Abstract
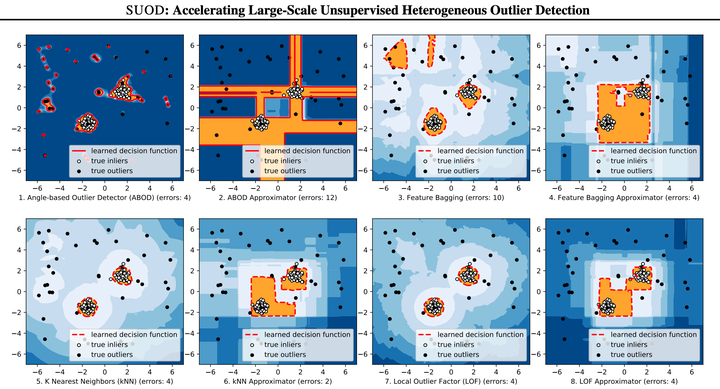
Outlier detection is a key field of machine learning for identifying abnormal data objects. Due to the high expense of acquiring ground truth, unsupervised models are often chosen in practice. To compensate for the unstable nature of unsupervised algorithms, practitioners from high-stakes fields like finance, health, and security, prefer to build a large number of models for further combination and analysis. However, this poses scalability challenges in high-dimensional large datasets. In this study, we propose a three-module acceleration framework called SUOD to expedite the training and prediction with a large number of unsupervised detection models. SUOD’s Random Projection module can generate lower subspaces for high-dimensional datasets while reserving their distance relationship. Balanced Parallel Scheduling module can forecast the training and prediction cost of models with high confidence—so the task scheduler could assign nearly equal amount of taskload among workers for efficient parallelization. SUOD also comes with a Pseudo-supervised Approximation module, which can approximate fitted unsupervised models by lower time complexity supervised regressors for fast prediction on unseen data. It may be considered as an unsupervised model knowledge distillation process. Notably, all three modules are independent with great flexibility to "mix and match"; a combination of modules can be chosen based on use cases. Extensive experiments on more than 30 benchmark datasets have shown the efficacy of SUOD, and a comprehensive future development plan is also presented.
{kind=link}