Abstract
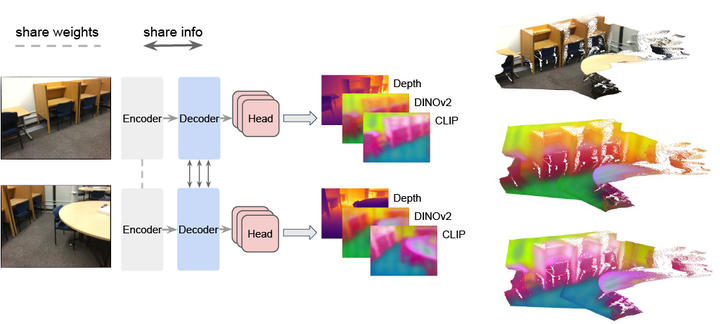
The emergence of 3D vision foundation models (VFMs) represents a significant breakthrough in 3D computer vision. However, these models often lack robust semantic understanding due to the scarcity of 3D-language paired data. In contrast, 2D foundation models, trained on abundant data, excel in semantic tasks. In this work, we propose a novel distillation approach, SAB3R, that transfers dense, per-pixel semantic features from 2D VFMs to enhance 3D VFMs. Our method achieves 2D semantic-aware feature integration while retaining the spatial reasoning capabilities of 3D VFMs. We validate our approach by showing that distillation does not compromise the base 3D foundation model, as demonstrated through evaluations on depth estimation and multi-view pose regression. Additionally, we introduce a new task, Map and Locate, to showcase the novel capability of multi-view 3D open-vocabulary semantic segmentation. Finally, our experiments reveal that SAB3R maintains a robust understanding of 3D structures while markedly improving 2D semantic comprehension. These results highlight the effectiveness of our approach.
{kind=link}